TDD
TDD – ang. Test-Driven Development jest to technika tworzenia oprogramowania, która polega na stworzeniu niedziałającego testu dla funkcjonalności którą chcemy dopiero napisać. Cały cykl pisania testu możemy podzielić na trzy kroki: Red-Green-Refactor.
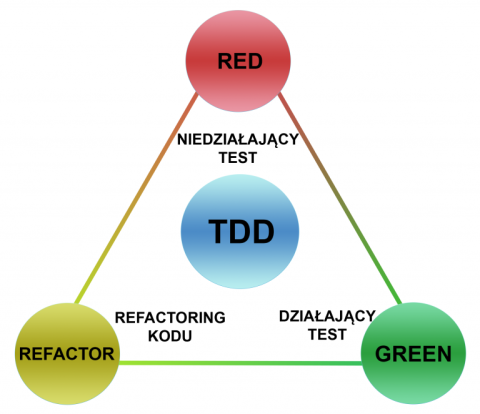
- Faza Red
Jest to faza w której mamy test który nie przechodzi. To pokazuje nam brakujące elementy w naszej implementacji lub też błędy w implementacji danej funkcjonalności dla której stworzyliśmy dany test. To zmusza nas do przemyśleń. - Faza Green
Jest to faza w której dodajemy minimalną część kodu produkcyjnego dzięki któremu nasz wcześniej niedziałający test staje się testem który już działa. - Refactor
Jest to faza w której dokonujemy refactoryzacji istniejącego już kodu, tak aby nie zmienić jego funkcjonalności.
Zalety:
- posiadamy automatyczne testy
- szybko wychwytujemy błędy w implementacji
- programista rozumie jak ma działać system lub funkcjonalność
- tworzymy szczegółową specyfikację
- dostajemy informacje czy ostatnia zmiana (lub refaktoryzacja) zepsuła wcześniej działający kod
- pozwala projektowi ewoluować i dostosowywać się do zmieniającego się problemu
- wymusza pisanie uproszczonego kodu
- zmusza do pisania małych klas skupionych na jednej rzeczy
- tworzymy kod łatwy w utrzymaniu, elastyczny i łatwo rozszerzalny
- testy jednostkowe są proste i działają jako dokumentacja kodu
- inny programista może postrzegać testy jako przykłady użycia i jak kod ma działać
- mniej błędów
Wady:
- poświęcamy dużo dodatkowego czasu na pisanie testów
- konieczność utrzymywania testów
- każda zmiana powoduje przepisanie lub zaktualizowanie testów
- testy nie mogą znaleźć błędów w kodzie testu
- jeśli choć jeden członek zespołu nie stosuje TDD to nie ma on sensu w projekcie
W poniższym filmiku podaje przykład zastosowania techniki TDD. W tym celu użyje frameworka JUnit5 , Mockito 2 oraz biblioteki Hamcrest.
Podczas pisania testów jednostkowych możemy spotkać się z sytuacją w której powinniśmy użyć pewnych danych np z zewnętrznego serwisu,ale jak na złość nie mamy do nich dostępu. Poza tym testy które by używały tych danych nie będą powtarzalne. Co za tym idzie nie opłaca się tego robić. Z pomocą w takich sytuacjach przychodzą: stuby, mocki oraz obiekty typu spy. Pokrótce opiszę każdy z nich.
Stub
Jest to obiekt który zawiera przykładową implementację imitującą działanie tej właściwej. Możemy użyć go w następujących sytuacjach:
- nie mamy dostępu do metody która zwróciłaby nam dane
- nie chcemy używać prawdziwych danych np ze względu na ewentualną ich modyfikację
Obiekty tego typu działają dobrze dla prostych metod i przykładów, ale przy większej liczbie warunków oraz zwiększeniu interfejsu nie działają już tak dobrze. Co za tym idzie mogą urosnąć do naprawdę dużych rozmiarów i tym samym być ciężkie w utrzymaniu. W poniższym filmiku pokazuje przykładowy kod.
Mock
Jest to obiekt który ma za zadanie symulować działanie rzeczywistego obiektu. Dodatkowo pozwala on na określenie jakich rezultatów spodziewamy się w trakcie testów, a następnie możemy sprawdzić czy są one zgodne z naszymi oczekiwaniami.
W porównaniu do stubów, mocki są tworzone dynamicznie w czasie działania testu co powoduje, że zapewniają one większą elastyczność oraz znacznie więcej funkcjonalności np weryfikacje wywołań metod. W poniższym filmiku pokazuje przykładowy kod.
Spy
Jest to obiekt hybrydowy – obiektów prawdziwych oraz mocków. W przypadku obiektu typu Spy możemy mockować wybrane metody. W rezultacie może być on częściowo normalnym obiektem i częściowo mockiem. W poniższym filmiku pokazuje przykładowy kod.
W moim przykładzie dodatkowo mieliśmy wykonać wyszukiwanie po nazwie. Przykładowa implementacja znajduje się w tym filmiku.